1. DLCM Architecture
The DLCM solution design is compliant with the OAIS model and follows current best practices of preservation. The solution architecture is open, flexible and modular so as to be scalable, sustainable, and to facilitate its integration with other information systems. How such integrations can be performed constitutes the topic of this document.
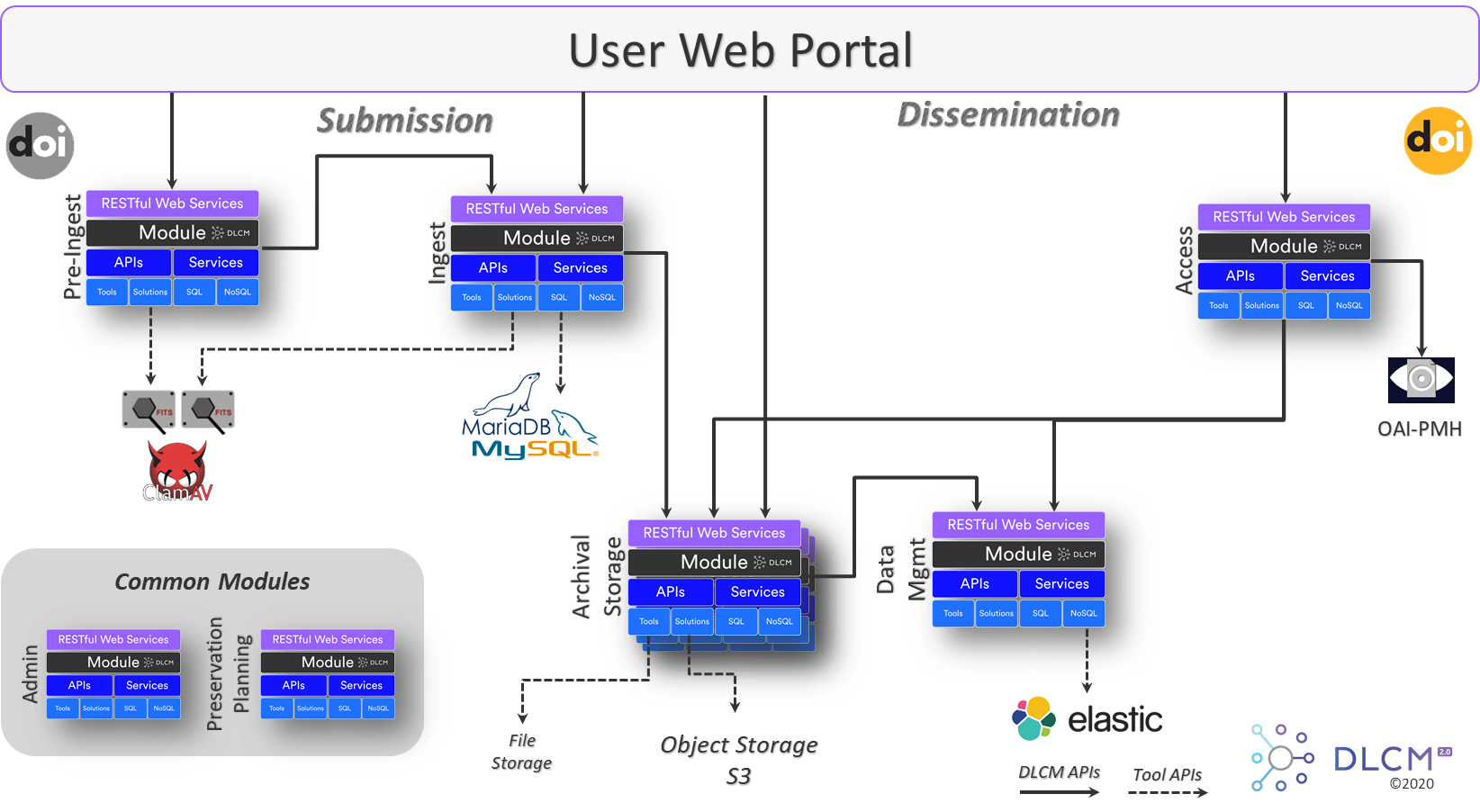
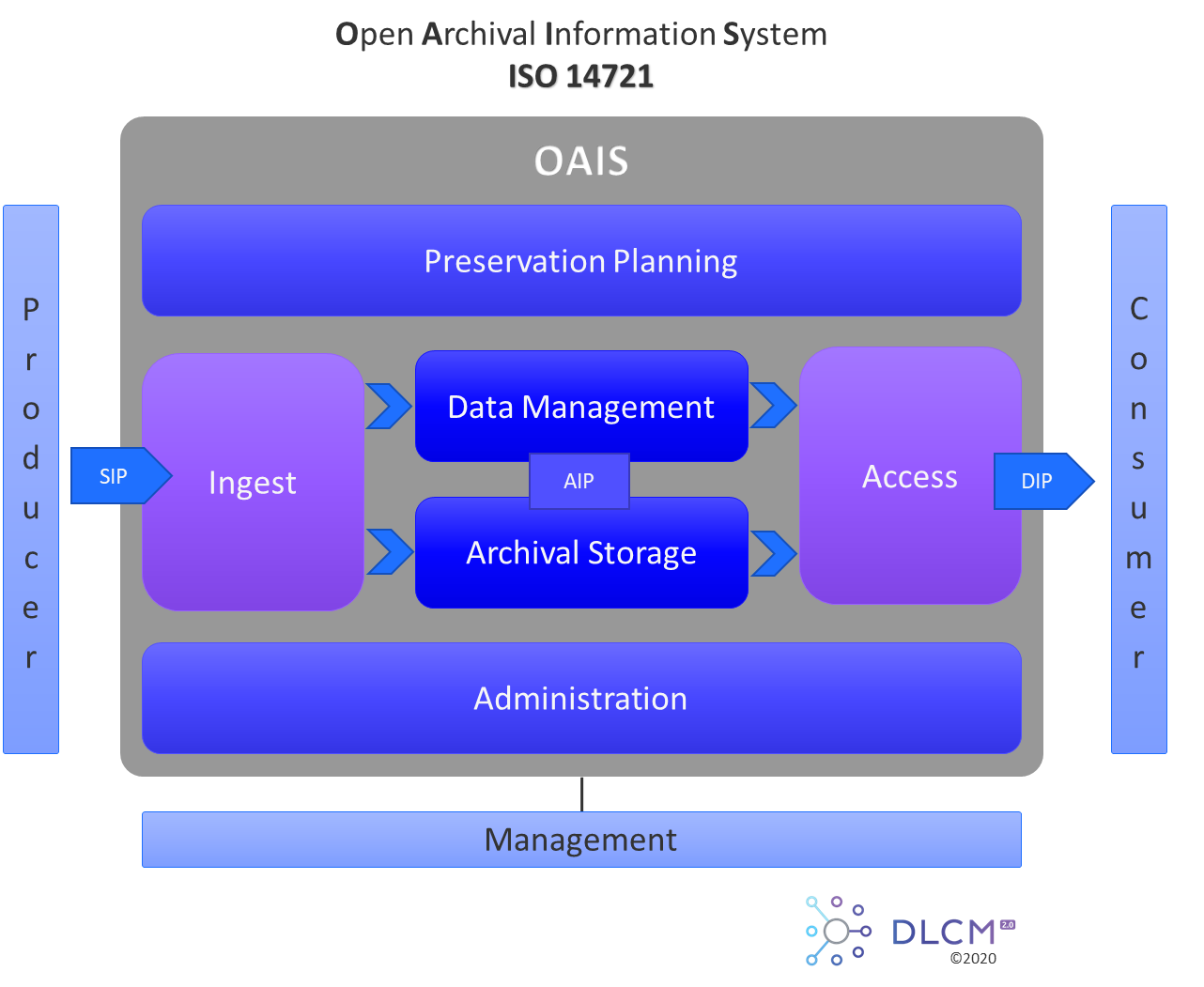
2. Integration Points
2.1. For Submission
There are three ways to deposit data files into the DLCM system:
-
By submitting individual data files
-
By using a package containing one or several data files
-
Based on a SIP (Submission Information Package)
See the details in Submission Integration section.
2.2. For Dissemination
Once the data files have been submitted and archived, the research community can access them:
-
By getting directly an archive with its ID
-
By searching on archive metadata
-
By exporting the AIP (Archival Information Package) through a DIP (Dissemination Information Package)
-
By exporting metadata with OAI-PMH protocol
See the details in Dissemination Integration section.
2.3. For Developers
-
All web services are detailed in API Documentation.
-
The API are available in OpenAPI format. See OpenAPI Tools. The definition is available in link:
-
The DLCM tools is a batch tool. The documentation is available in DLCM Tools Documentation.
3. REST Web Services
3.1. Overview
The DLCM APIs are RESTful web services based on the best practices. The implementation corresponds to the third level of Leonard Richardson’s Maturity Model:
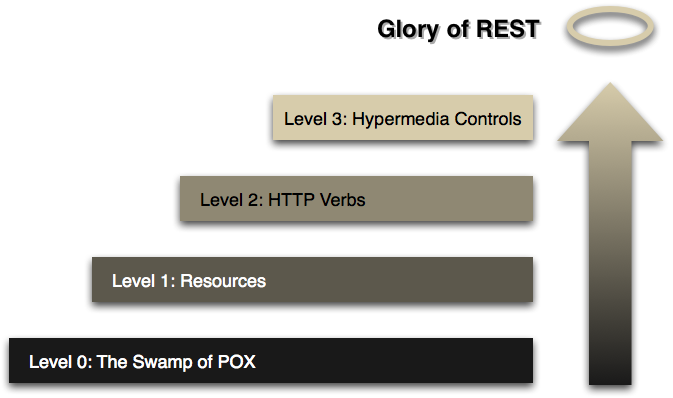
Source : (crummy.com, 2008)
More details about these concepts are available on the following links:
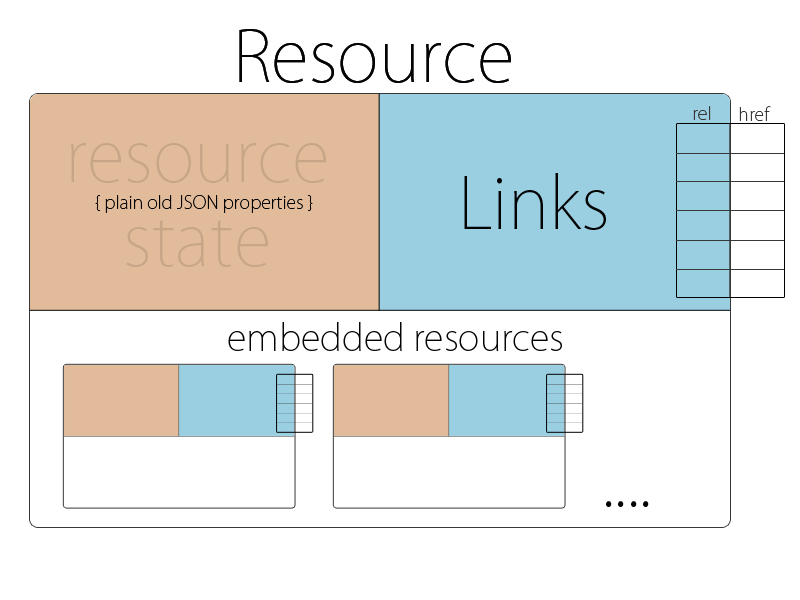
Source : (stateless.co, 2011)
3.1.1. URL Structure
The URL of each REST resource is constructed according to the following rule:
http(s)://<root context>/<module>/<things>
Where:
-
http(s)is the protocol which can be secured depending on the installation configuration. -
<root context>is the root context of the application, defined in the configuration. -
<module>is the functional module (see DLCM Architecture): the different module names are detailed in the DLCM Modules section in the Annexes. -
<things>is the name of the REST resource: it must be a *noun in plural form*.
The naming convention, applied only for <things>, respects the camel case syntax, with a lower case character for the first one.
| There are some examples of root contexts in the demo environment |
3.1.2. CRUD Operations
By default, for each REST resource, the CRUD actions are available like this:
| HTTP verb | CRUD action | Collection | Instance |
|---|---|---|---|
|
Create |
✔ |
✘ |
|
Read |
✔ |
✔ |
|
Update No creation |
✘ |
✔ |
|
Delete |
✘ |
✔ |
The HTTP verb for an action on a resource is POST:http(s)://<root context>/<module>/<things>/<thingID>/<action>.
|
3.1.3. HTTP Status Codes
RESTful notes tries to adhere as closely as possible to standard HTTP and REST conventions in its use of HTTP status codes.
| Status code | Usage |
|---|---|
|
The request completed successfully |
|
A new resource has been created successfully. The resource’s URI is available from the response’s
|
|
An update to an existing resource has been applied successfully |
|
The request was malformed. The response body will include an error providing further information |
|
Authentication is required to access to this resource |
|
You are not allowed to access to this method for this resource |
|
The requested resource did not exist |
|
The requested method is not supported for this resource |
3.1.4. Error Details
{
"path": "http(s)://<root context>/<module>/<things>",
"status": "BAD_REQUEST",
"error": "Type of error",
"message": "Message to explain the issue",
"timeStamp": "DDD MMM YY hh:mm:ss CEST YYYY",
"statusCode": 400
}Contains the malformed request information, which describes the problem on the request:
-
The path field is the url of the resource concerned by the problem.
-
The status field is the status of the request (always 'BAD_REQUEST' in this case).
-
The error field is the error that occurs on the request.
-
The message field is the message that details the problem.
-
The timeStamp field is the time at which the error occurred.
-
The statusCode field is the status code of the request (always '400' in this case) .
In the case in which a body object is provided, the validationErrors field is also added to the fields above. The value of this field is an array that contains for each malformed field:
-
The fieldName field that contains the name of the malformed field.
-
The errorMessages field array that contains the list of errors in this field.
| Example of a deposit submission with a malformed body = {} |
{
"path": "http(s)://<root context>/<module>/<things>",
"status": "BAD_REQUEST",
"error": "None",
"message": "Validation failed",
"timeStamp": "Fri May 17 11:39:15 CEST 2019",
"validationErrors": [
{
"fieldName": "title",
"errorMessages": [
"can't be null"
]
},
{
"fieldName": "description",
"errorMessages": [
"can't be null"
]
},
{
"fieldName": "organizationalUnitId",
"errorMessages": [
"can't be null"
]
}
],
"statusCode": 400
}| Example of a malformed deposit submission with no body |
{
"path": "http(s)://<root context>/<module>/<things>",
"status": "BAD_REQUEST",
"error": "Required request body is missing: ...",
"message": "Request not readable",
"timeStamp": "Fri May 17 12:53:29 CEST 2019",
"statusCode": 400
}| Example of a malformed deposit submission with a body = [] |
{
"path": "http(s)://<root context>/<module>/<things>",
"status": "BAD_REQUEST",
"error": "JSON parse error: ...",
"message": "Request not readable",
"timeStamp": "Fri May 17 13:04:39 CEST 2019",
"statusCode": 400
}3.2. Collection
A collection of REST resources is a list of JSON objects. The list has its own structure, is paginated, filterable and sortable.
The collection URL is:
http(s)://<root context>/<module>/<things>.
3.2.1. Structure
{
"_data" : [
{ "object" : "#1" },
{ "object" : "#2" },
{ "object" : "#3" },
{ "object" : "#4" }
],
"_page": {
"currentPage" : 0,
"sizePage" : 20,
"totalPages" : 1,
"totalItems" : 4
},
"_links" : {
"self" : {
"href" : "URL of the collection"
},
"module" : {
"href" : "URL of the DLCM module"
}
}
}Data Section
The Data section contains an array of JSON representations, corresponding to business objects (i.e. things). The details of these objects can be found in the technical documentation (i.e. API Documentation) provided with the DLCM solution.
Page Section
The Page section contains the pagination information, which describes the current position:
-
The currentPage field is the page number of the current page: it starts at 0.
-
The sizePage field is the size of each page: the default is set to 20, the max value is 2000.
-
The totalPages field is the total number of pages for the current page size.
-
The totalItems field is the total number of objects for the current selection.
Links Section
The Links section contains the links corresponding to the current collection. This list is dynamic and depends on the state of the collection:
-
The self link is the current URL: it is always present.
-
The module link is the URL to access the current module.
-
The next link is the URL to go to the next page, available only if it exists.
-
The previous link is the URL to go to the previous page, available only if it exists.
-
The lastCreated link is the URL to get the list sorted by creation date in descending order.
-
The lastUpdated link is the URL to get the list sorted by last update date in descending order.
-
Some other links could be available depending on the current resource: these links are detailed in the API documentation of the resource.
| Example of institution list |
{
_data : [
{
resId : "7f9df7bb-5eab-4823-98a0-abb668731de5",
name : "UNIGE",
description : "Université de Genève",
},
{
resId : "18284eb1-de0b-427e-9e8c-c541cb35e818",
name : "EPFL",
description : "Ecole Polytechnique Fédérale de Lausanne",
},
{
resId : "e8a9b74d-7b84-4958-be62-9b0b1d83a360",
name : "ETH",
description : "ETH Zürich",
}
],
_page : {
currentPage : 0,
sizePage : 20,
totalPages: 1,
totalItems: 4
},
_links: {
self : {
href : "http://localhost:16105/dlcm/admin/institutions"
},
module : {
href : "http://localhost:16105/dlcm/admin"
},
lastCreated : {
href : "http://localhost:16105/dlcm/admin/institutions?sort=creation.when,desc"
},
lastUpdated : {
href : "http://localhost:16105/dlcm/admin/institutions?sort=lastUpdate.when,desc"
}
}
}3.2.2. Usage
To get a list of things
The different parameters can be used individually or together.
Request |
|
|
|---|---|---|
Verb |
GET |
|
Parameter(s) |
Name |
Description |
|
The page size |
|
|
The current page number |
|
|
To apply a filter on a field
if the field is embedded in a sub structure, the field name must be fully named with “.” for each level:+
|
|
|
To sort a field |
|
Expected |
|
Success |
Return Object |
JSON Collection object |
See Structure |
| Examples |
-
To filter by creation date:
http(s)://<root context>/<module>/<things>?sort=creation.when -
To sort by most recent objects:
http(s)://<root context>/<module>/<things>?sort=creation.when,desc -
To get page 10 composed of 5 elements:
http(s)://<root context>/<module>/<things>?page=10&size=5
3.3. Instance
The instance of REST resource is the instance of an object with its fields.
The instance URL is:
http(s)://<root context>/<module>/<things>/<thingID>.
3.3.1. Structure
{
"creation" : {
"when" : "Creation date & time",
"who" : "Creation user"
},
"lastUpdate" : {
"when" : "Last update date & time",
"who" : "Last update user"
},
"resId" : "Object ID",
"fields" : "Object fields...",
"_links" : {
"self" : {
"href" : "URL of the object"
},
"list" : {
"href" : "URL of the object collection"
},
"module" : {
"href" : "URL of the DLCM module"
},
"Other link" : {
"href" : "Others links of the object"
}
}
}The field list elements are:
-
The creation and lastUpdate fields, containing the information of the action:
-
The when field is the date and the time, with milliseconds of the action (ex : 2018-03-08T17:42:30.733+0100).
-
The who field is the user id of the user who has done the action.
-
-
The resId field is the identifier of the object: it is a UUID.
-
Some other fields complete the object description: these fields are detailed in the technical documentation of the resource.
Links Section
The links section contains a list of links of the object:
-
The self link is the URL of the current object.
-
The list link is the URL pointing to the object collection.
-
The module link is the URL to access the current module.
-
Some other links could be available depending on the object: these links are detailed in the technical documentation of the resource.
| Example of an institution |
{
"creation" : {
"when" : "2018-03-08T17:42:30.733+0100",
"who" : "user id of user xxxxxx"
},
"lastUpdate" : {
"when" : "2018-03-08T17:42:30.733+0100",
"who" : "user id of user yyyyyyy"
},
"resId" : "7f9df7bb-5eab-4823-98a0-abb668731de5",
"name" : "UNIGE",
"description" : "Université de Genève",
"_links" : {
"self" : {
"href" : "http://localhost:16105/dlcm/admin/institutions/7f9df7bb-5eab-4823-98a0-abb668731de5"
},
"list" : {
"href" : "http://localhost:16105/dlcm/admin/institutions"
},
"module" : {
"href" : "http://localhost:16105/dlcm/admin"
},
"people" : {
"href" : "http://localhost:16105/dlcm/admin/institutions/7f9df7bb-5eab-4823-98a0-abb668731de5/people"
},
"organizationalUnit" : {
"href" : "http://localhost:16105/dlcm/admin/institutions/7f9df7bb-5eab-4823-98a0-abb668731de5/organizationelUnits"
}
}
}3.3.2. Usage
To get a resource
Request |
|
|
|---|---|---|
Verb |
GET |
|
Parameter(s) |
Name |
Description |
|
- |
|
Expected |
|
Success |
|
Not found |
|
Return Object |
JSON object |
See Structure |
To create a new resource
Request |
|
|
|---|---|---|
Verb |
POST |
|
Parameter(s) |
Name |
Description |
|
Object in JSON format. The fields and the structure depend on the type: see API Documentation |
|
Expected |
|
Created |
Return Object |
|
See Structure |
To update a resource
The resource must already exist.
Request |
|
|
|---|---|---|
Verb |
PATCH |
|
Parameter(s) |
Name |
Description |
|
Object in JSON format. The fields and the structure depend on its type: see API Documentation |
|
Expected |
|
Modified |
|
Not modified |
|
|
Not found |
|
Return Object |
|
See Structure |
To delete a resource
Request |
|
|
|---|---|---|
Verb |
DELETE |
|
Parameter(s) |
Name |
Description |
|
- |
|
Expected |
|
Deleted |
|
Not found |
|
|
Gone |
|
Return Object |
|
If success |
3.4. Security
3.4.1. Authentication
All web services are secured and require authentication.
User authentication relies on Switch AAI which is a Single Sign-On (SSO), based on Shibboleth.
Access to Web services relies on OAuth 2.0 access delegation.
OAuth 2.0 is a protocol allowing third-party applications to grant limited access to an HTTP service, either on behalf of a resource or by allowing the third-party application to obtain access on its own. It uses the authorization code grant implementation.
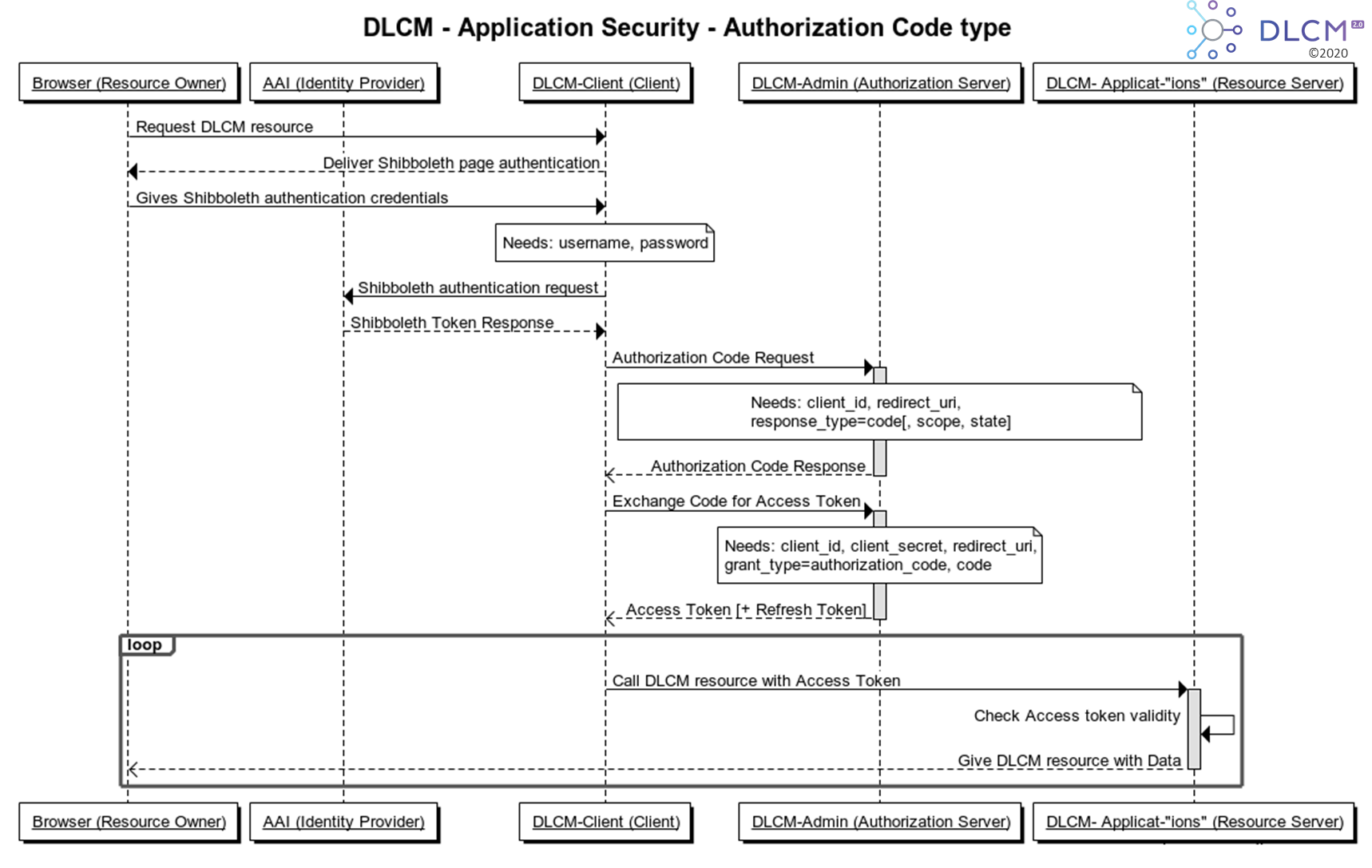
3.4.2. Application Roles
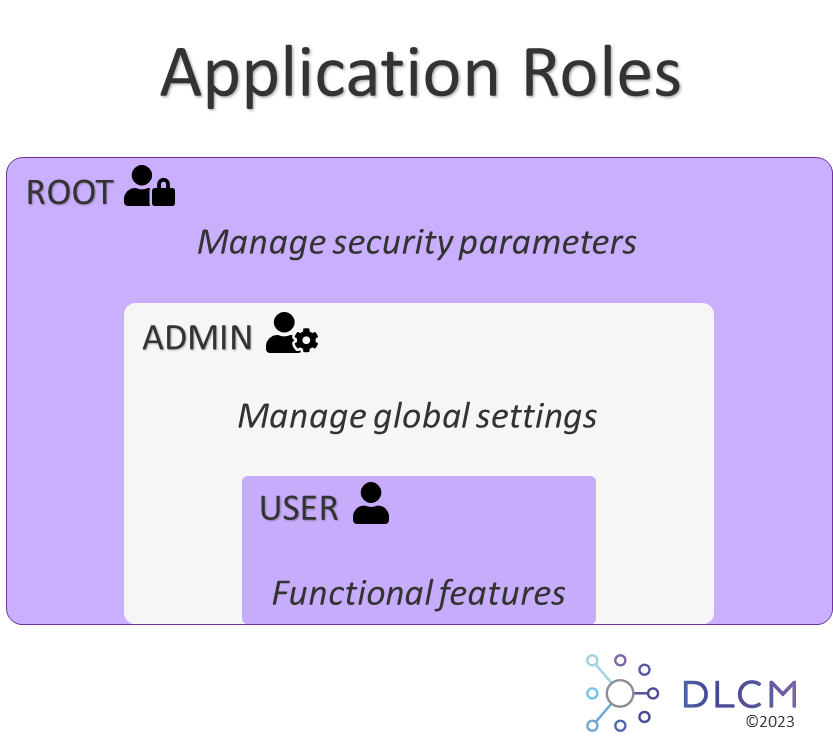
The features are organized in:
-
Functional features list for an user
-
Organizational Units, Deposits, Search, etc…
-
-
Global settings list for an administrator
-
Organizational units, People, Institutions, Funding agencies, Submission policies, Preservation policies, Licenses, etc…
-
-
Security parameters list for a root
-
System Configuration, User Roles, Users, etc…
-
See details in Application Roles.
3.4.3. Roles
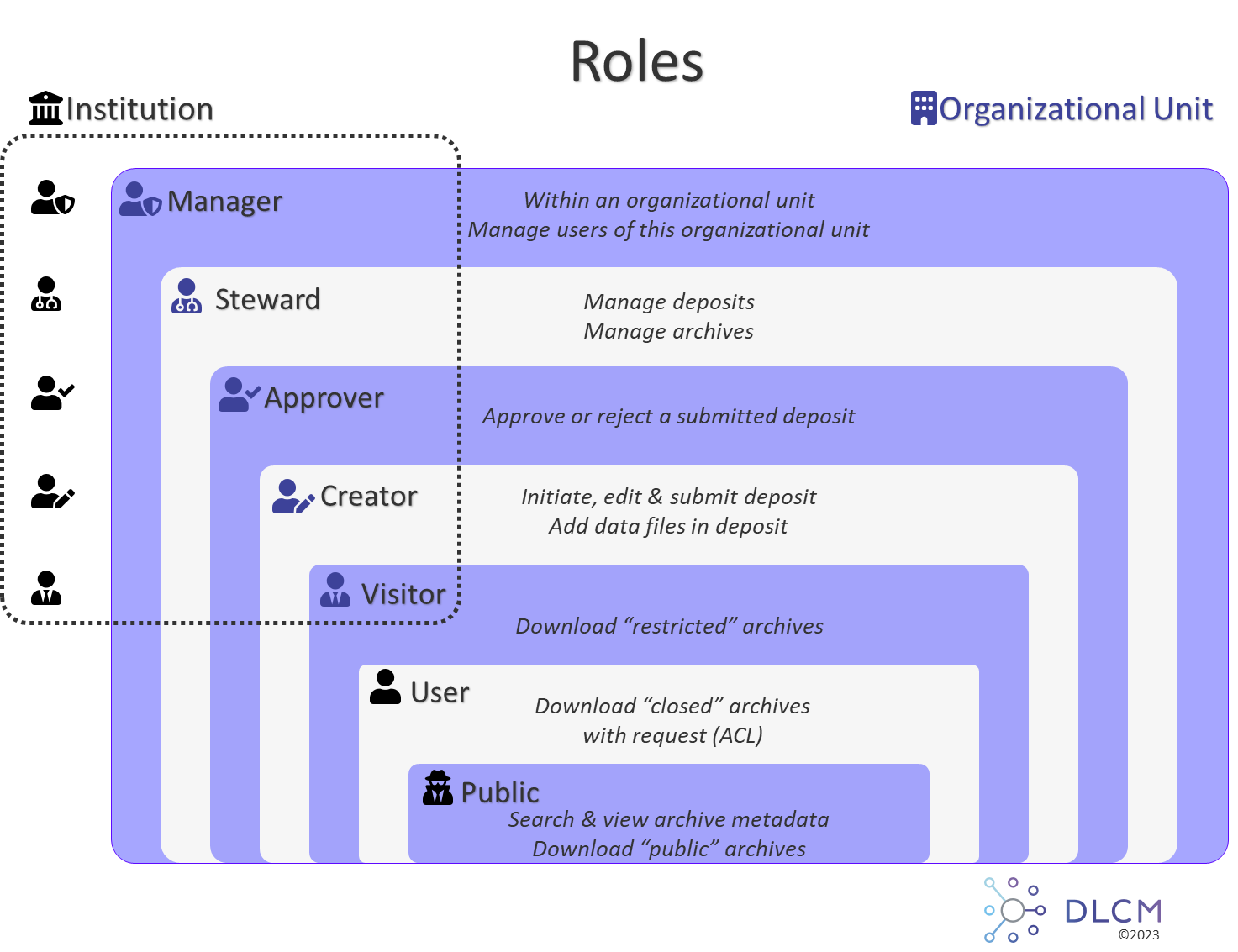
A role can be inherited from an institution if an organizational unit is linked to this institution.
For example, if an manager of an institution or an administrator gives the steward role to an user, this user will became the steward of all organizational units of this institution.
See details in Roles.
Organizational Unit Definition
-
An organizational unit is a logical entity where managers can define security rules:
-
Who can submit deposits?
-
Who can download archives?
-
-
Could be a research project, a laboratory, a department or any other organizational group of researchers.
4. Data Access
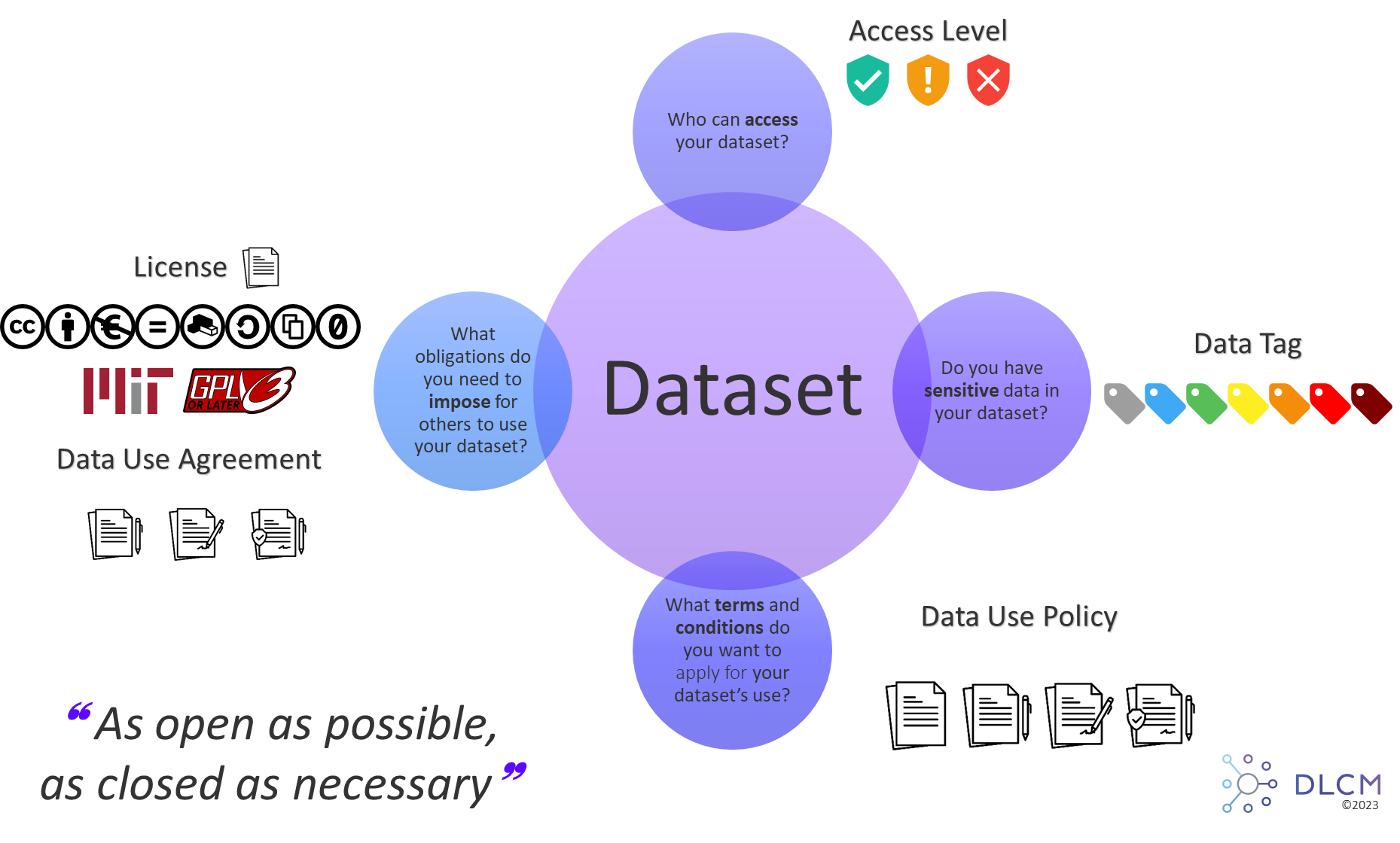
When data must be archived, at the ingestion, some questions must be answered:
| 1 | Who can access the archive? ⇒ Define the correct level of Access Levels |
| 2 | Are there sensitive data in the archive? ⇒ Define the correct tag of Data Tags |
| 3 | What are terms & conditions to use the archive? ⇒ Define the correct policy of Data Use Policies |
| 4 | What are obligations to impose for using the archive? ⇒ Choose the license or specify the data use agreement |
4.1. Data Access Scales
Each concept (access level, data tag or data use policy) have a restriction scale to control the access to the archives: from less to more restrictive.
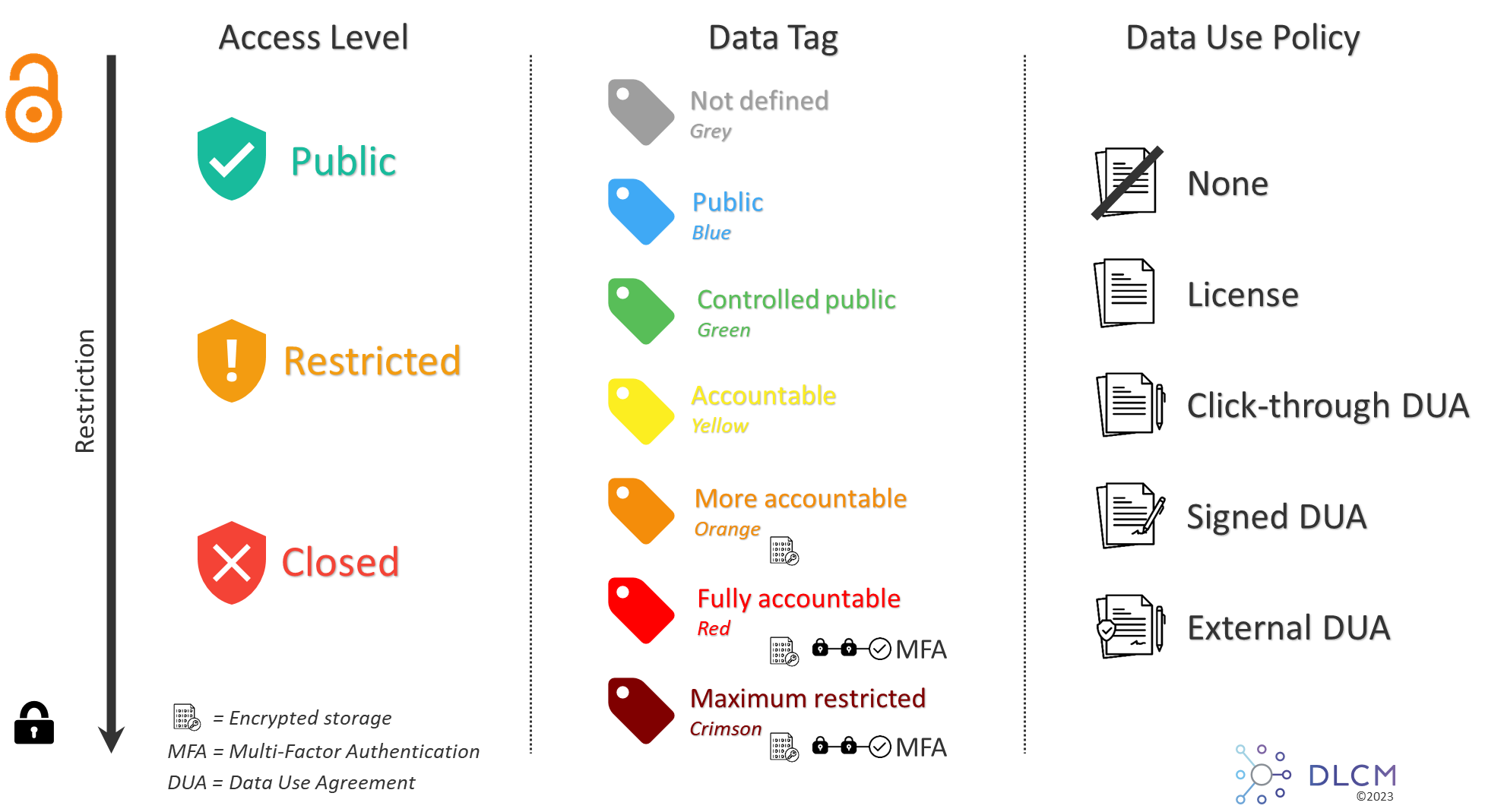
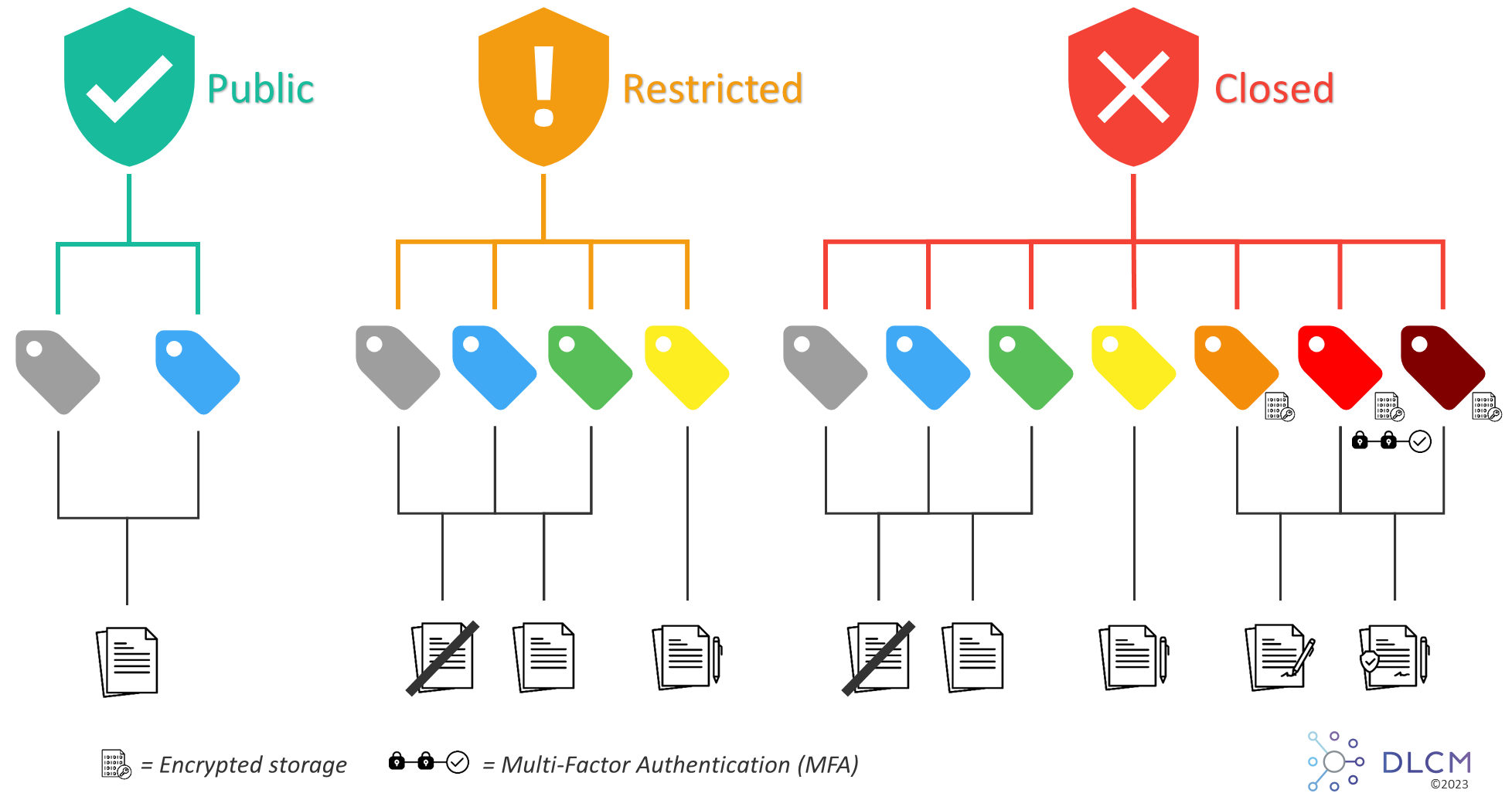
4.2. Data Access Compatibility
The compatibility between those concepts are described in the following matrix.
5. Submission Integration
5.1. Overview
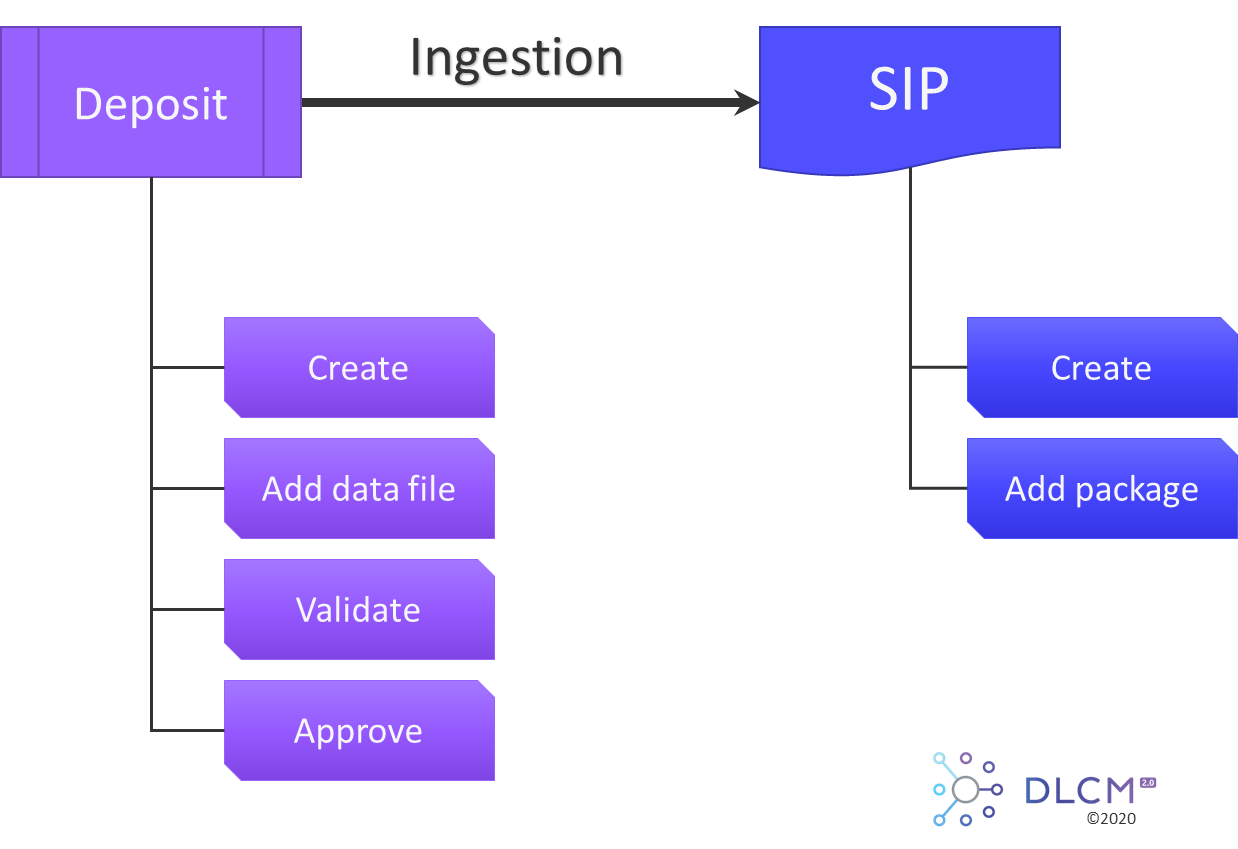
The ingestion process consists either in the creation of a deposit based on a wizard-like assisted approach, or in using a ready-to-use SIP.
5.2. Wizard-like assisted deposit
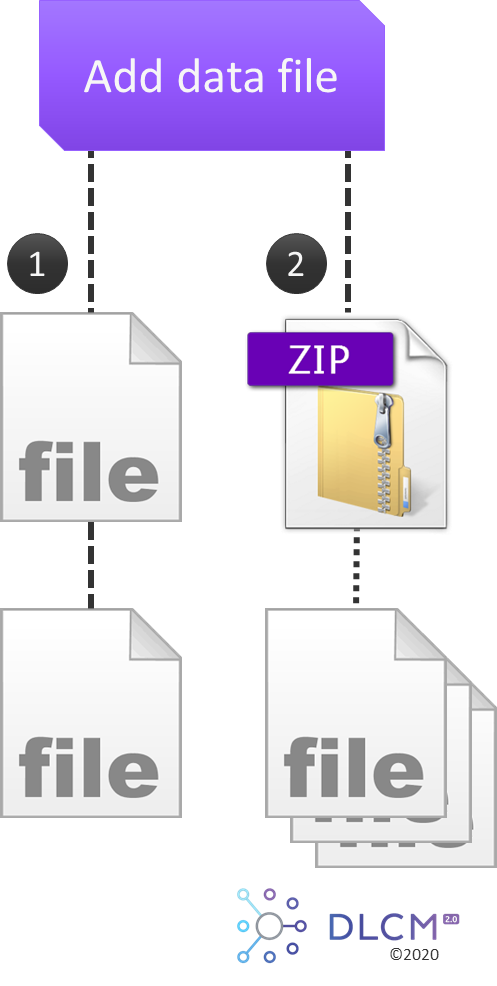
The deposit operation consists in gathering all data files and the information necessary to create a SIP package. The objective of the wizard is to structure the deposit and to categorize each data file:
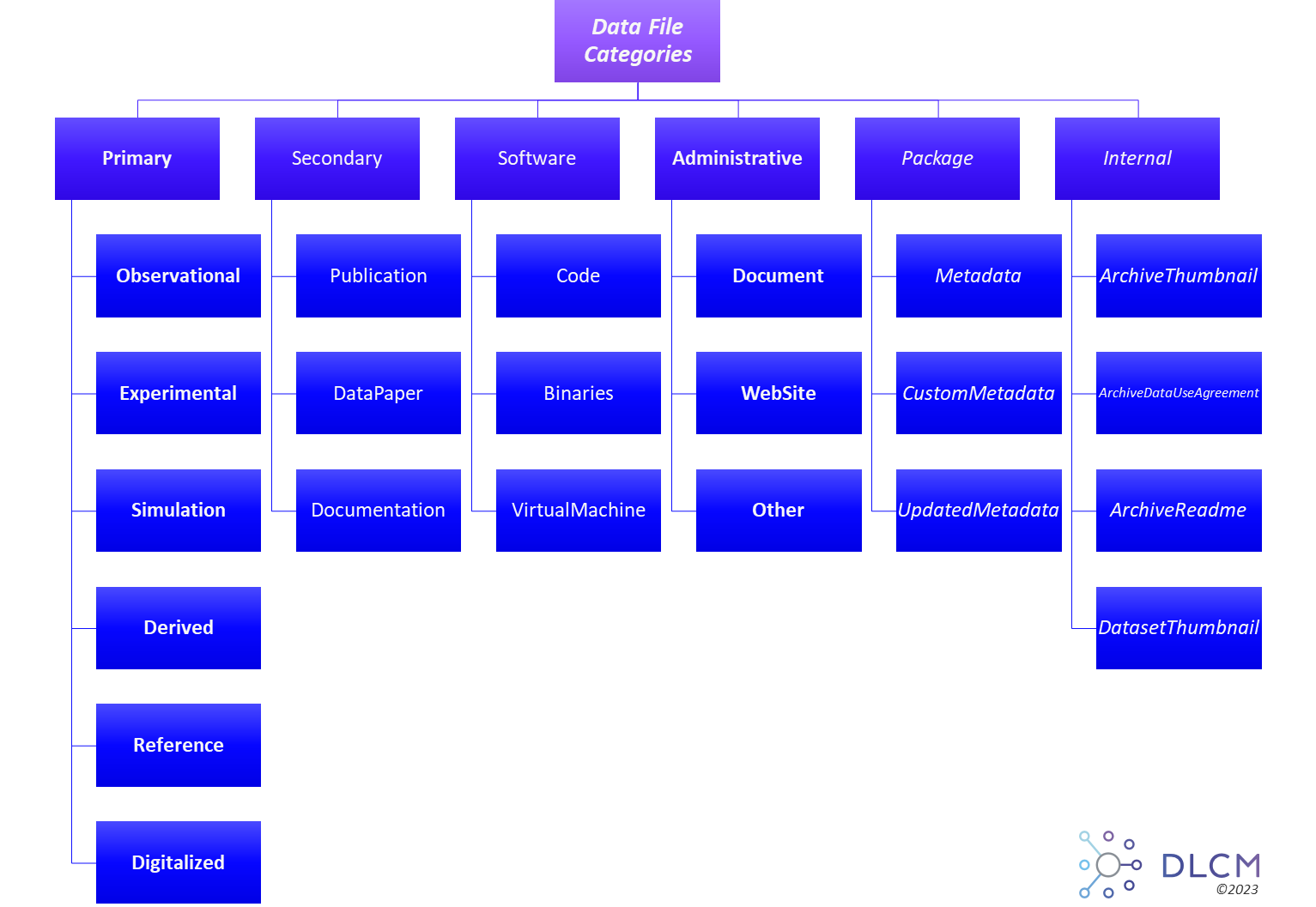
The description of each category is detailed at the Data File Categories section in the Annexes.
The data file assignment to a deposit can be done file-by-file (mode ❶) or by batch (mode ❷):
5.2.1. To create a deposit
Request |
|
|
|---|---|---|
Verb |
POST |
|
Parameter(s) |
Name |
Description |
|
See Deposit section in API Documentation |
|
Expected |
|
Created |
Return |
|
See Deposit section in API Documentation |
Roles |
Creator (see Roles) |
|
| Deposit example |
The minimal set of information for a deposit is:
{
"organizationalUnitId" : "Organizational unit ID of the data set",
"title" : "Data set title",
"year" : 2018,
"description" : "Data set description"
}5.2.2. To deposit data files
To add data files to a deposit, the first option (mode ❶) is to deposit them one-by-one.
By creating an URI
It’s possible to provide a URI (useful for large files).
Request |
|
|
|---|---|---|
Verb |
POST |
|
Parameter(s) |
Name |
Description |
|
See Data File section in API Documentation |
|
Expected |
|
Created |
Return |
|
See Data File section in API Documentation |
Roles |
Creator (see Roles) |
|
The effective download of the referenced data (see API Documentation) is done asynchronously by the “Pre-Ingest” module, which supports the file (for files on local file systems), http and https protocols.
By uploading a file
Request |
|
|
|---|---|---|
Verb |
POST |
|
Content-type |
|
|
Parameter(s) |
Name |
Description |
|
Data file to upload |
|
|
Data file category (see Data File Categories section in the Annexes) |
|
|
Data file sub-category (see Data File Categories section in the Annexes) |
|
|
Sub-folders of data file |
|
Expected |
|
Created |
Return Object |
|
See Data File section in API Documentation |
Roles |
Creator (see Roles) |
|
If the data file is the descriptive metadata of the dataset, it must respect the deposit metadata schema. If not, the data file will have a status In-Error.
5.2.3. To deposit a data files package
The second option (mode ❷) is to add data files in a deposit by batches. The batch mode supports zip files, containing all the data files to upload, including sub-folders.
Request |
|
|
|---|---|---|
Verb |
POST |
|
Content-type |
|
|
Parameter(s) |
Name |
Description |
|
Zip file which contains data files |
|
|
Data file category (see Data File Categories section in the Annexes) |
|
|
Data file sub-category (see Data File Categories section in the Annexes) |
|
Expected |
|
Created |
Return |
|
See Data File section in API Documentation |
Roles |
Creator (see Roles) |
|
5.2.4. To get the deposit metadata schema
Request |
|
|
|---|---|---|
Verb |
GET |
|
Parameter(s) |
Name |
Description |
|
- |
|
Expected |
|
Success |
Return |
|
XML schema file |
Roles |
All (see Roles) |
|
5.2.5. To submit a deposit for approval
This step is optional. It depends of submission policy if an approval is expected.
Request |
|
|
|---|---|---|
Verb |
POST |
|
Parameter(s) |
Name |
Description |
|
- |
|
Expected |
|
Modified |
|
Not modified |
|
|
Not found |
|
Return |
|
Action result |
Roles |
Creator (see Roles) |
|
5.2.6. To approve a deposit
Request |
|
|
|---|---|---|
Verb |
POST |
|
Parameter(s) |
Name |
Description |
|
- |
|
Expected |
|
Modified |
|
Not modified |
|
|
Not found |
|
Return |
|
Action result |
Roles |
Approver (see Roles) |
|
5.3. By using a SIP
5.3.1. To create a SIP
Request |
|
|
|---|---|---|
Verb |
POST |
|
Parameter(s) |
Name |
Description |
|
See SIP section in API Documentation |
|
Expected |
|
Created |
Return |
|
See SIP section in API Documentation |
Roles |
Creator (see Roles) |
|
| SIP example |
The minimal set of information for an SIP is:
{
"info" : {
organizationalUnitId" : "Organizational unit ID of the SIP",
"name" : "Name of the SIP",
"description" : "Description of the SIP"
}
}5.3.2. To submit a SIP package
Request |
|
|
|---|---|---|
Verb |
POST |
|
Content-type |
|
|
Parameter(s) |
Name |
Description |
|
The Zip file must contain a metadata XML file and at least one data file. |
|
Expected |
|
Created |
Return |
|
See Data File section in API Documentation |
Roles |
Creator (see Roles) |
|
The SIP metadata file must be in XML and respect the SIP metadata schema.
5.3.3. To get SIP metadata schema
Request |
|
|
|---|---|---|
Verb |
GET |
|
Parameter(s) |
Name |
Description |
|
- |
|
Expected |
|
Success |
Return |
|
XML schema file |
Roles |
All (see Roles) |
|
6. Dissemination Integration
6.1. To search archives
Request |
|
|
|---|---|---|
Verb |
GET |
|
Parameter(s) |
Name |
Description |
|
Query criteria |
|
Expected |
|
Success |
Return |
|
List of Archive information & DataCite metadata (see [archive-example]) with pagination |
Roles |
Public (see Roles) |
|
|
Query examples:
|
6.2. To get an archive
6.2.1. By archive ID
Request |
|
|
|---|---|---|
Verb |
GET |
|
Parameter(s) |
Name |
Description |
|
- |
|
Expected |
|
Success |
Return |
|
Archive information & DataCite metadata (see [archive-example]) |
Roles |
Public (see Roles) |
|
| Archive public metadata example |
{
"resId": "<archiveID>",
"index": "<index name>",
"type": "metadata",
"metadata": {
"aip-disposition-approval": "<true/false>",
"aip-organizational-unit": "<organizational unit ID>",
"aip-retention": "<retention duration in days",
"aip-retention-end": "<retention end date>",
"aip-unit": "<true/false>",
"aip-size": "<archive size>",
"creation": "<creation date>"
"datacite.xml": "<DataCite XML>",
"aip-container": "BAG_IT",
"datacite": {
<DataCite JSON>
}
}
}6.2.2. By DOI
Request |
|
|
|---|---|---|
Verb |
GET |
|
Parameter(s) |
Name |
Description |
|
DOI to search |
|
Expected |
|
Success |
Return |
|
Archive information & DataCite metadata (see [archive-example]) |
Roles |
Public (see Roles) |
|
6.3. To download an archive
To download an archive, several steps are needed:
-
To check if a download request exists and to know its status: To get download status
-
To create a download request: To prepare download
-
To download the archive: To download archive content
6.3.1. To get download status
Request |
|
|
|---|---|---|
Verb |
GET |
|
Parameter(s) |
Name |
Description |
|
- |
|
Expected |
|
Success |
|
Not found ⇒ To prepare download |
|
Return |
|
|
Roles |
Public (see Roles) |
|
6.3.2. To prepare download
Request |
|
|
|---|---|---|
Verb |
POST |
|
Parameter(s) |
Name |
Description |
|
- |
|
Expected |
|
Accepted |
Return |
- |
|
Roles |
Public (see Roles) |
|
6.3.3. To download archive content
Request |
|
|
|---|---|---|
Verb |
GET |
|
Parameter(s) |
Name |
Description |
|
- |
|
Expected |
|
Success |
Return |
|
|
Roles |
Public (see Roles) |
|
6.4. To export metadata with OAI-PMH
The OAI-PMH provider of DLCM solution supports version 2.0 of the protocol for metadata harvesting. The specifications are detailed on the Open Archives Initiative website.
Request |
|
|
|---|---|---|
Verb |
GET or POST with content-type application/x-www-form-urlencoded |
|
Parameter(s) |
Name |
Description |
|
||
|
Optional parameter to display OAI XML in a structured way, with XML transformation to generate HTML. |
|
Expected |
|
Success |
|
Service unavailable, i.e. the Data Management module is not running |
|
Return |
|
OAI-PMH XML data. See OAI-PMH specifications |
Roles |
Public (see Roles) |
|
7. Annexes
7.1. Glossary
| Acronym | Description | Source |
|---|---|---|
AIC |
Archival Information Collection |
OAIS |
AIP |
Archival Information Package (i.e. Archive) |
OAIS |
AIU |
Archival Information Unit |
OAIS |
API |
Application Programming Interface |
Software |
CRUD |
Create Read Update Delete |
Software |
Deposit |
Research data deposit |
DLCM |
DIP |
Dissemination Information Package |
OAIS |
HAL |
Hypertext Application Language |
Software |
HATEOAS |
Hypermedia As The Engine Of Application State |
Software |
IP |
Information Package |
OAIS |
JSON |
JavaScript Object Notation |
Software |
OAIS |
Open Archival Information System |
OAIS |
REST |
REpresentational State Transfer |
Software |
SIP |
Submission Information Package |
OAIS |
SOA |
Service Oriented Architecture |
Software |
7.2. DLCM Modules
| Module | Description | REST Name |
|---|---|---|
Pre-Ingest |
Pre-Ingest module to prepare a deposit in SIP |
preingest |
Ingest |
Ingest module to check an SIP and to transform it into an AIP |
ingest |
Archival Storage |
Archival Storage module to check an AIP and to store it |
archival-storage |
Data Mgmt |
Data Management module to index metadata |
data-mgmt |
Access |
Access module to manage queries/request and to generate a DIP |
access |
Preservation Planning |
Preservation Planning module to manage preservation activities |
preservation-planning |
Admin |
Administration module to manage general settings |
admin |
7.3. Application Roles
| Icon | Application Role | Description |
|---|---|---|
|
|
A root is the super administrator of the application. |
|
|
An administrator can configure the application by defining new parameters, like license or preservation policy. |
|
|
An user is a person who have to use the application. |



7.4. Roles
Icon |
Role |
Within an institution |
Within an organizational unit |
|
|
He can manage users of this institution. |
He can manage users of this organizational unit, |
|
|
He has the steward role for all organizational units of the institution. |
He has the steward role for the organizational unit. |
|
|
He has the approver role for all organizational units of the institution. |
He has the approver role for the organizational unit. |
|
|
He has the creator role for all organizational units of the institution. |
He has the creator role for the organizational unit. |
|
|
He has the visitor role for all organizational units of the institution. |
He has the visitor role for the organizational unit. |
|
|
A user is an authenticated person (with a login/password) on the application. |
He has no permission on any organizational unit. |
|
|
A public is not authenticated on the application. |
He has no permission on any organizational unit. |








7.5. Access Levels
| Icon | Access Level | Description |
|---|---|---|
|
|
The archive is accessible to everyone |
|
|
The archive is accessible to team members (i.e., Org. Unit) |
|
|
The archive is accessible case by case thank to access control list (ACL) |



7.6. Data Tags
| Icon | Tag Type | Description | Transfer | Storage | Access | Requirement Support | Access Level Compatibility |
|---|---|---|---|---|---|---|---|
|
|
Not defined |
|
|
- |
|
All |
|
|
Public |
|
|
Open |
|
All |
|
|
Controlled public |
|
|
Email, OAuth verified registration |
|
|
|
|
Accountable |
|
|
Password, Registered , Approval, click-through DUA |
|
|
|
|
More accountable |
|
|
Password, Registered, Approval, signed DUA |
|
|
|
|
Fully accountable |
|
|
Two-factor Authentication, Registered, Approval, signed DUA |
|
|
|
|
Maximum restricted |
|
|
Two-factor Authentication, Registered, Approval, signed DUA |
|
|







| DUA = Data Use Agreement |
Sources:
7.7. Data Use Policies
| Icon | Data Use Policy | Description |
|---|---|---|
|
|
No data use policy. No constraint. |
|
|
A license is mandatory. |
|
|
A DUA is mandatory. It is stored in the archive and is approved when the user click to request access. |
|
|
A DUA is mandatory. It is stored in the archive. It must be downloaded, signed and provided when the user request access. |
|
|
A DUA is mandatory. But, it is managed and stored externally, so not in the archive. The control is done outside the application. |





| DUA = Data Use Agreement |
7.8. Deposit Status
| Status | Description |
|---|---|
|
The deposit has been approved. |
|
The deposit has been checked. |
|
The deposit has been cleaned: all date files have been purged. |
|
A clean job is currently running. |
|
The deposit has been archived. |
|
The deposit has been created. |
|
The deposit is in error. An action must be done to fix the deposit. |
|
The deposit is open to add data files. |
|
The deposit must be validated. |
|
The validation process has rejected the deposit. |
|
The deposit process is started. |
7.9. Data File Categories
| Category | Sub-Category | Description |
|---|---|---|
Primary |
Primary Data category |
|
Observational |
Data captured in real-time, usually irreplaceable. For example, sensor data, survey data, sample data, neuro-images. |
|
Experimental |
Data from lab equipment, often reproducible, but can be expensive. For example, gene sequences, chromatograms, toroid magnetic field data. |
|
Simulation |
Data generated from test models where model and metadata are more important than output data. For example, climate models, economic models. |
|
Derived |
Data is reproducible but expensive. For example, text and data mining, compiled database, 3D models. |
|
Reference |
A (static or organic) conglomeration or collection of smaller (peer-reviewed) datasets, most probably published and curated. For example, gene sequence databanks, chemical structures, or spatial data portals. |
|
Digitalized |
Digital version of analogue objects. For example, manuscripts, books. |
|
Secondary |
Secondary Data category |
|
Publication |
Research publication or article |
|
DataPaper |
Research data paper |
|
Documentation |
Other documentation |
|
Software |
Software category |
|
Code |
Code or programs |
|
Binaries |
Binaries or executables |
|
VirtualMachine |
Images of virtual machines |
|
Administrative |
Administrative category |
|
Document |
All kinds of documents |
|
WebSite |
Web sites |
|
Other |
Others types of files |
|
Package |
DLCM Package category |
|
InformationPackage |
DLCM Package (internal used only) |
|
Metadata |
DLCM metadata in XML format |
|
CustomMetadata |
Specific metadata of a research in JSON or XML format |
|
UpdatedMetadata |
DLCM updated metadata in XML format |
|
UpdatePackage |
DLCM Updated Package (internal used only) |
|
Internal |
DLCM Archive category |
|
DatasetThumbnail |
Dataset Thumbnail (for archive version < 3.1) |
|
ArchiveThumbnail |
Archive Thumbnail (for archive version >= 3.1) |
|
ArchiveReadme |
Archive README |
|
ArchiveDataUseAgreement |
Data Use Agreement (DUA) for archives with sensitive data |
|
|
The categories are dependent on the configuration.
|
7.10. Data File Status
| Status | Description | Action |
|---|---|---|
|
An update of the data category or of the data type is in progress. |
n/a |
|
An update of the relative location is in progress. |
n/a |
|
The data file is purged after a clean job. |
n/a |
|
A clean job is currently running. |
n/a |
|
The data file has been created. |
n/a |
|
The data file has a forbidden format. |
This data file must be deleted before submitting deposit. |
|
The file format identification ran successfully. |
n/a |
|
The file format identification was skipped because of the file size. |
n/a |
|
The file format identification failed. |
n/a |
|
The data file has a format which needs a action. |
This data file must be deleted or validated before submitting deposit. |
|
The data file is in error. |
An action must be done to fix the data file. |
|
The data file has been processed: downloaded or copied. |
n/a |
|
The data file processing is completed. |
n/a |
|
The data file is created. |
n/a |
|
The data file is created, before to be processed. |
n/a |
|
The virus check ran successfully: no virus. |
n/a |
|
The virus check was skipped because of the file size. |
n/a |